


Machine learning is revolutionizing many industries and forever changing how we interact with computer systems and each other. The revolution is occurring in cyber security, where machine learning is already being applied to assist human analysts and security experts ingest and make sense of increasingly large amounts of data so that they can identify threats and make decisions as to how best to mitigate vulnerabilities. While this symbiotic relationship is improving our security posture, it is fundamentally limited by humans making decisions at human speed. Significant gains in security can be made if autonomy is embraced and “trusted” machine learning is given license to make actionable decisions at machine speed. Despite the potential benefits, there have been relatively few research efforts and applications of autonomous machine learning towards cyber security applications. The purpose of this article is to make the case for increased research and development of autonomous control machine learning approaches in the cyber domain. In it, we discuss emerging autonomous machine learning technologies and their recent successes, technical and non-technical challenges that still need to be overcome for practical autonomous applications of machine learning, and finally some thoughts on potential near-term applications of autonomous machine learning to cyber security.
Introduction
Where machine learning was once the topic of discussion only in academic circles and research communities, it is now commonplace and, seemingly, applied to every domain imaginable. New products or breakthroughs using machine learning are announced every day. It is a truly transformative technology with the potential to dramatically improve and even reshape our daily lives. Machine learning has applications to all sectors of business, including industry, commercial, healthcare, banking, and national defense. It is quite literally the driving technology behind recent advances in autonomous vehicles and the core of smart assistants, automated stock traders, and medical diagnostics.
Continual advances in machine learning have transformed voice recognition and text-to-speech from angrily screaming at Siri to Amazon Echoes and Google Homes in millions of homes across the world. Machine learning is the technology that allows Google and Amazon to predict what you want to search for or buy with such absurd accuracy that it seems like they can read your mind. Promises of grand advancements brought about by machine learning are the reasons why world-wide investment in machine learning and artificial intelligence (AI) is estimated to be $19.1 billion dollars in 2018 by the International Data Corporation and expected to surpass $50 billion by 2021 [1].
The rapid advancements in machine learning have piqued interest and inspired further research. This progress has been made possible by the technical convergence of three key factors: (1) cheap and readily available High-Performance Computing (HPC), (2) novel advances in computational models including distributed architectures and deep learning, and (3) the rise of “Big Data”. Advances in HPC, particularly the advent of General-Purpose Graphics Processing Units (GPGPU), have allowed researchers to construct and train significantly larger and more complex machine learning models on commodity hardware than was possible on expensive and private HPC super computers just a decade earlier. Newer distributed architectures and training algorithms, such as Deep Neural Networks (DNNs) and stochastic gradient descent, are more capable than prior non-deep methods. Finally, as a product of information age, “Big Data” has provided researchers with plentiful, high-quality, large-scale datasets that have made it possible to train large, complex machine learning models effectively.
Given these advances, data that was previously idle can inform security, improve efficiency, among other innovations that were not possible just a few years ago. The potential applications and benefits of machine learning are so far reaching and impactful that every business and organization should be cognizant of developments and making strategic investments in machine learning or run the risk of becoming surpassed and antiquated by those that do.
What is Machine Learning
In a nutshell, machine learning encompasses any automated computational process for extracting knowledge from data and applying it to make decisions. Knowledge, in many cases, is a generalization about the target problem. For example, you might want to use machine learning to automatically determine if a new piece of software contains malware. Many forms of malware contain common components or features that are distinct from benign software, which makes it plausible to learn a way of differentiating malware and benign software from existing examples of both. Machine learning uses these examples to learn a decision boundary that can predict whether a new piece of software is malware.

Figure 1 provides a simplified illustration of this process. In the figure, features of the malware and benign software samples are used to sort where they lie in a two-dimensional (2D) space. The machine learning algorithm then examines this data using statistical analysis and models to find the optimal way to separate data from the two classes, shown in the figure as the decision boundary. New pieces of software are then plotted in this 2D-space and the decision boundary is used to predict whether the software is malware – if the point lies above the boundary, it predicts malware and vice-versa. While this example is overly simplified, it illustrates the machine learning process in which an algorithm uses data and a model – a line in this case – to learn generalized information and make an informed decision.
Types of Machine Learning
There are several different types of machine learning. One key distinguishing feature is whether the data includes labels or “ground-truth”.
- Supervised Learning: In this form of machine learning, algorithms are tasked with learning some function over the data. An example function could be: given a house, predict the value of the house. This learning is “supervised” because it requires data that has ground truth (i.e., the correct answer) to learn the function. Supervised learning is powerful and arguably the most commonly used form of machine learning. The example provided in Figure 1 is an example of supervised learning. Unfortunately, data is usually labeled manually which is a costly and potentially error-prone endeavor.
- Unsupervised Learning: In “unsupervised” learning, there are no labels. Instead of attempting to learn a function, these methods attempt to learn patterns or other generalizations from the data. Pattern recognition and clustering are examples of this form of machine learning. Unsupervised learning is advantageous because it does not require labeled data, but the lack of labels limit the inferences that can be derived.
- Reinforcement Learning: Reinforcement learning is distinct from the other two types of machine learning and is used to solve very different problems. Instead of solving single-step decision problems (e.g., is this software malware?), reinforcement learning is used to find solutions to multi-step decision problems, such as navigating from point A to point B. Unlike supervised learning, reinforcement learning does not require labeled data to train on, but unlike purely unsupervised learning, it does require feedback to inform the algorithm. Specifically, the algorithm needs to know whether an action was good or bad to reinforce the behavior, hence the name reinforcement learning. Amazingly, through this feedback, reinforcement learning algorithms can autonomously learn to solve very complex real-world problems. Reinforcement learning is a major focus of this article and we will spend more time discussing it in later sections.
Machine Learning and Cyber Security
As in many other domains, machine learning is being actively researched and applied to cyber security with great effect. It has already proven to be extremely useful in helping security professionals handle their problems with “Big Data” more effectively to stay one step ahead of adversaries. In the realm of cyber security, administrators and security personnel can become inundated exorbitant amounts of data (terabytes to petabytes of data per day for some organizations) to assess the security of their organization. Machine learning provides an accurate and cost-effective way of distilling valuable information from that data to allow them to make informed and effective decisions.
There are numerous ways in which machine learning is currently being used to improve cyber security. Automatic and robust malware detection with machine learning is a very active area [2] [3] [4], similar to the example in the Introduction. Machine learning is being used to greatly enhance anomaly and insider threat detection [5] [6]. It is being researched to automatically detect and mitigate botnet threats, such as the Mirai botnet that took down much of the Internet on the Eastern seaboard in 2016 [7] [8]. Machine learning is also the underlying technology behind the recent advances in biometric authentication that are being used to increase the security of our networks and personal devices such as smartphones [9].
While great progress has been made towards applying machine learning to cyber security, there is still plenty to be done along current research vectors and even greater potential, such as robust, adaptive, autonomous control. Existing research and applications of machine learning to cyber security make great use of machine learning to characterize and identify security threats from large disparate sources of data; however, in the end, it is up to a human analyst or security manager to make actionable decisions on that information. These decisions are made at human decision speeds, understandably, and are critically dependent to the knowledge and skill of the person in control. If instead, the machines themselves were licensed to make informed actionable decisions then networks and computer systems could anticipate and respond to threats and problems at machine speeds and do so with consistency across multiple systems drastically improving their security posture. Relatively little research has been done in this area because there are many significant challenges, some technical and some not, which must be overcome. However, if successful, intelligent, autonomous security systems will revolutionize computer security.
Reinforcement Learning: Decision to Action
Machine learning can do much more than just aid analysts in making actionable decisions to improve a security posture. It can also learn how to make those decisions autonomously and effectively in increasingly more complex domains. This is where reinforcement learning comes in. Reinforcement learning is a distinct form of machine learning that automatically learns how to act in the world. The algorithm learns “policies” – prescriptive functions that, given the current observable state of a problem, determine the best next course of action. Reinforcement learning algorithms can do this automatically by learning over data from past experiences trying different actions under various conditions. Using a prespecified performance feedback signal, reinforcement learning algorithms can determine which actions work best under specific circumstances. Once deployed, reinforcement learning algorithms can learn autonomously and adapt to novel and previously unseen conditions by using newly gathered experience data.
Reinforcement Learning: How it works
Observation Space: Commonly known as the state space, this describes what the reinforcement learning agent can see and observe about the world to use in its decision-making process
Actions: This is a set of actions the agent can choose from and execute as part of its policy.
Reward Signal: This provides both positive and negative reinforcement to the agent and informs the learning algorithm as to whether actions are leading to favorable or unfavorable outcomes.
Although the learning process is mostly automatic, the problem must be specified to the reinforcement learning algorithm manually and carefully. For every reinforcement learning problem there are three (3) basic elements that must be specified:
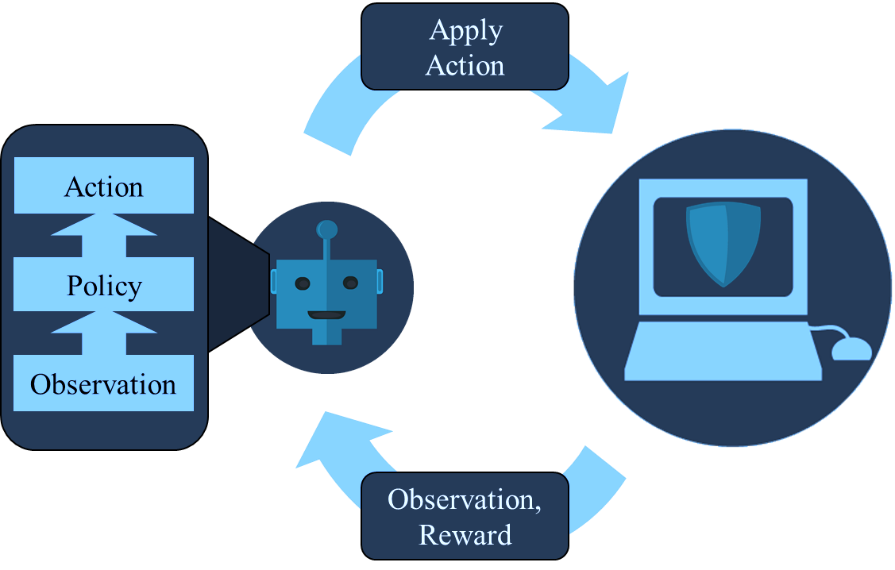
Figure 2 provides a graphical depiction of how reinforcement learning works in general within the context of a security problem. In this example, a reinforcement learning agent, represented by the robot, is tasked with maintaining and optimizing the security posture and function of a computer system, represented by the computer icon. The reinforcement learning agent can execute various actions, such as running scans, backups, examining logs, and other administrative functions, to accomplish this task. At any given moment, the agent determines what action to execute next by querying its policy with an observation of the current state of the environment. Using this observation, the policy selects best action to take, learned from prior experiences. This action is then applied in the operating environment resulting in a new experience comprised of the next observation and feedback in the form of a positive or negative reward correlating to whether an action is good or bad regarding the security posture of function of the machine. The new experience is added to the agent’s experience repository and can be used to learn an updated policy. Finally, the most recent observation is used to query the policy again, and the process continues iteratively.
Reinforcement learning is an exceptionally powerful technology in that it allows the machine to automatically determine how best to solve complex long-term problems. As such, reinforcement learning algorithms can provide robust control solutions that learn the specifics of the problems they are applied to and can adapt to unforeseen or unexpected situations. The autonomous and self-optimizing nature of the algorithms allows reinforcement learning algorithms to succeed in complex dynamic domains where human derived heuristics are too difficult to specify or maintain.
The Rise of Reinforcement Learning and Games
Given all the positive advantages of reinforcement learning, why is reinforcement learning not used everywhere? The answer lies in the history of machine and reinforcement learning. Until recently, research in reinforcement learning had made relatively little headway towards making it a practically viable technology. Research had been almost entirely relegated to solving simple toy problems and making small incremental improvements to theory and algorithms. One notable exception was a world-class backgammon playing reinforcement learning-based computer playing program called TD-Gammon that learned how to play at a master level through self-play in the 1990’s [10]. This all changed in 2013 when, a (then) small obscure startup with grand ambitions of creating a general-purpose AI, called DeepMind, developed and released a new deep learning-based reinforcement learning approach called Deep Q-learning Network (DQN) [11]. DQN amazed by learning to play Atari games as well as, or in a few cases better than, human players. Playing Atari may not sound impressive initially, but if one considers a single DQN model is able to learn and play the entire library of Atari games with no prior knowledge or special interface (it uses the raw video) the achievement becomes much more impressive. It demonstrated that reinforcement learning can be combined with emerging deep learning methods to automatically learn important features of environment and execute exclusively through observation. That seemingly simple feat was enough to get Google’s attention, who purchased the company for half a billion dollars [12].

Things became even more interesting in 2016 when DeepMind released AlphaGo, a deep learning reinforcement learning-based approach that plays the ancient Chinese board game of Go. Prior to the release of AlphaGo, leading researchers predicted that developing an AI that could play Go as well as a human was at least 20 years away. The best AI’s at the time could only play at a novice level on miniature boards. In comparison to chess, for which AI’s had famously surpassed humans in 1998 with IBM’s Deep Blue, Go has an astronomically greater number of possible positions and moves. This prohibits the use of clever search heuristics that worked for chess. Instead, AlphaGo uses deep-reinforcement learning (similar to DQN), simulated rollouts of what could happen a few moves in advance, and extensive self-play, in which the algorithm trained playing against itself, to learn to play the game. Unlike prior AIs, AlphaGo could play full sized games and DeepMind was confident enough in its AI that it challenged the world’s best players. In March of 2016 AlphaGo famously defeated the reigning world champion, Lee Sedol, 4-1 on its first attempt [13].
Reinforcement Learning and Cyber Security
While developing an algorithm that can defeat human players is impressive, it has limited practical applications.
Common features include:
How can gaming algorithms be transitioned to the real-world?
Fortunately, many cyber security control problems share several aspects with games that are critical to the successful application of reinforcement learning, such as ease of simulation, active adversaries (opponents), and easily-defined rewards.
- Can be Simulated: Current reinforcement learning methods require extensive experience to learn effective policies. One of the best ways to gain that experience quickly and cheaply is through simulation, where it is safe to try all available actions. Go and Atari games can be perfectly simulated with ease to allow for near-infinite accumulation of experience. Many cyber domains, unlike physical domains, can also be simulated with high fidelity allowing a reinforcement learning agent to gain the necessary extensive experience in a safe environment.
- Adversaries: Security domains assume the presence of adversaries – opponents in games. Reinforcement learning can learn to defeat adversaries very effectively, including ones that learn.
- Easily-defined rewards: In games, the feedback/reward signal is very straightforward. The player wins, loses, or scores points. Reinforcement learning can readily use this signal to learn effective policies. In cyber security control domains, there are often equally apparent reward signals. For example, metrics such as detected threats, disruptions, and utilization, among others, are easily quantified and can be optimized by a reinforcement learning algorithm.
The commonalities between cyber security control problems and games should make the application of reinforcement learning much easier than in many other real-world domains. Despite this, reinforcement learning has made surprisingly little progress in tackling realistic cyber security problems. There have been some preliminary research efforts in the area such as using reinforcement learning to defend against DDoS attacks [14] or defeating network intrusions [15]. In each of these works, both the approach and problems they address are overly simplified and do not provide real solutions. The failure of such research efforts likely boils down to inadequate domain and reinforcement learning expertise. Without domain expertise, it is difficult to properly define the actual problem. Consequently, the problem solved does not represent the true problem. Conversely, without reinforcement learning expertise in state-of-the-art methods (e.g., DQN) it is notoriously difficult to apply them. This can result in domain experts incorrectly applying off-the-shelf algorithms that are ill-suited to solving their complex real-world problems. Solving real-world cyber security problems with reinforcement learning requires pairing extensive domain expertise with machine learning experts and some generous funding. If we can do this correctly, the results will be transformative.
Practical Considerations: Challenges and Pitfalls
Successfully applying reinforcement learning in any domain is a challenging and risky endeavor that is riddled with frustrating and time-consuming obstacles that can derail even the most skilled and well-thought-out approaches. Fortunately, the payoffs greatly outweigh the risks and many of these obstacles are common across domains, allowing us to learn from the failures and experiences of others in much the same way as a reinforcement learning solution would. The following sections discuss a few of these common hurdles and practical considerations that researchers and practitioners regularly run into. We offer insights and guidance for future endeavors based on our experience applying reinforcement learning to the cyber domain.
Pitfalls in describing problems to computers
While machines are getting objectively smarter, as of this writing, they are still exceptionally dumb. Before a machine can be set upon the task of learning how to solve any reinforcement learning problem it must first be told precisely what the problem is. It must be told exactly what it can see or observe, what it can do and when, and how to measure success and failures. Despite the development of formal processes and well understood models for defining problems to machine learning algorithms, this task remains arguably the most difficult and critical to any machine learning project. There are simply an innumerable number of ways in which to mess it up.
One extreme is that the problem definition can be over-specified, which will result in the learning system solving narrow instances and not the whole problem of interest. For instance, consider a navigation task of navigating from point A to point B. If the source, A, and destination, B, points are always fixed in the same locations, the learner will likely only learn a policy specific to navigating between those points and not a generalized policy for navigating between any two points. Alternatively, one can just as easily under specify the problem and the task. In this case, if the problem description is too vague it may render learning a hopeless exercise. Referring to the navigation example, if the learning system is tasked with navigating to point B but is not given any indication as to where B is, it may never find where it needs to go. Bottom line, getting the problem specification wrong results in inadequate solutions and, in some cases, spectacular failures. These are just a few examples of ways defining problems can go wrong, there are many more.
Success in defining a reinforcement learning problem starts by putting considerable thought and effort into what makes up the task and what a viable solution would accomplish. This is what having subject matter expertise in the problem brings to the table. Without a solid understanding of what the intricacies of a problem are and what a solution looks like it is near impossible to define it correctly. From this understanding, the problem description can be properly scoped and defined such that the computer only concerns itself with relevant aspects of the problem and efficiently learns generalizable solutions. Thus, reinforcement learning expertise is vitally important. Knowing how to effectively scope a problem and define a learnable objective is something that comes from experience.
With those key experiential ingredients in place, the formal process for describing a reinforcement learning problem is to define it as what is known as a Markov Decision Process (MDP). A MDP is a mathematical description of a multi-step problem. We will not delve into any of the math behind MDPs, but we will discuss the 4 components and what should be considered while defining them.
A MDP is comprised of a state-space, action-space, reward function, and discount factor. The state-space determines what the algorithm can see or monitor when learning a solution to the problem. Given the current state, the algorithm should have access to all the information it needs to make a decision. It is made up of a set of observable features relevant to solving the problem. For example, in a robotic navigation task, the state-space should include the current position of the robot as a feature and the location of the destination.
When designing the state-space it is imperative that only relevant features be included and the amount of redundancy across features be minimized. The reason this is crucial is that size of the state-space has an inverse relationship with the solvability of the defined problem. It suffers from what is known as the “curse of dimensionality.” This means for every added feature the dimensionality increases, which increases the size and difficulty of solving the problem exponentially.
Until recently, incorporating more than a handful of features in a state-space made most problems intractable by reinforcement learning methods. Fortunately, recent advances in representation learning, specifically deep learning, have made it possible to solve problems with hundreds of state features. Representation learning methods, working in concert with reinforcement learning (e.g., DQN), automatically learn generalizations across large areas of a state-space that dramatically reduce the complexity and difficulty of the policy learning problem. These methods should be used in tackling any practical problem.
An action-space defines all the possible actions a reinforcement learning algorithm can take as part of a policy and the conditions under which those actions are valid. In the robotic navigation task an action-space could be comprised of the set of actions: move forward, backward, turn left, turn right, or do nothing. Similar to the state-space, it also suffers from the “curse of dimensionality.” Thus, an action space should be both concise and complete.
The reward function is the feedback signal the reinforcement learning algorithm uses to learn and optimize policies. It is a metric of value that tells the algorithm the relative value of every state in the state-space. If the agent achieves something good (i.e. reaches a goal state) it should be rewarded with a positive signal. Alternatively, if it does something bad (i.e. crashes) it should be penalized with a negative signal. Also, any intermediary states (i.e. on the road) should have a neutral value and the algorithm can still figure out the sequence of actions and states that eventually lead to positive or negative rewards.
Designing a reward signal carefully is important as it is what ultimately dictates the behavior of the learned policy. Consideration must be made to ensure that the agent will not learn an undesirable policy. For example, in a robotic navigation task, if the reward function rewards for reaching the goal in as short a distance possible, the agent may learn a policy that arbitrarily runs over pedestrians because they were on the shortest path.
Finally, the discount factor is a parameter that adjusts how much the algorithm values long-term vs. short-term rewards. Different values for this parameter will change the behavior of learned policies.
Gaining experience even when failure is not an option
Machine learning algorithms require data to learn – lots of data. Reinforcement learning is no exception; however, it uses experiences as its data. An experience, for a reinforcement learning algorithm, is taking an action in a given state and observing the outcome.
The algorithm needs a representative set of experiences trying various actions in different states to learn a policy that sufficiently covers the problem. In practice, this presents challenging problems – where is all the experience data going to come from and how do we get it? Further, reinforcement learning algorithms needs positive and negative experiences to learn. For example, an autonomous vehicle that cannot reach a target location is no more useful than one that cannot avoid pedestrians. If negative experiences have real costs (e.g., crashing a car), we must determine if those costs are acceptable and under what conditions.
Where and how do we get data? One of the major reasons reinforcement learning has been so successful in understanding games is that they can be simulated perfectly. This affords algorithms the opportunity to gather nearly infinite experience at negligible costs. If simulation is plausible, it is, definitively, the best way to gather experience; however, most real-world problem domains, particularly physical environments, cannot be simulated with sufficiently high-fidelity to allow policies learned in simulation to generalize well to real environments. Additionally, the cost of obtaining real-world experience data, in terms of money, time, and risk, can be too great to make learning policies from scratch practical.
Hope for reinforcement learning in realistic domains that cannot be simulated is not lost. Many real-world problems that could be solved by reinforcement learning algorithms are already being performed by people. Reinforcement learning algorithms can learn from experiences of others. If the reinforcement learning algorithms observe and record the experiences of, assumed intelligent, people they can use those experiences to bootstrap and learn policies that are as effective, or possibly even more effective, than the ones used by people. This form of reinforcement learning is called learning from demonstration and it is a practical approach to reduce risk in gathering experience. While it does not reduce the amount of experience required, it does reduce the inherent risk in allowing the algorithm to enact potentially unsafe actions. As the tasks are already being performed by people, the experience gathering comes at little additional cost. Further, if the learning systems are deployed as part of a mixed-initiative system, where both human operators and the machine can make decisions, it proves to be mutually beneficial. The computer would benefit from direct feedback from the operator and the operator can benefit from improved reaction times and, potentially, insights provided by the computer. Such a mixed-initiative system could even be designed to provide justification to an operator for each decision, which would go a long way towards improving trust in autonomous learning systems.
Trust in Autonomy: Giving the robot the keys to your car
The prospect of autonomous learning machines is both exciting and a bit frightening. A fundamental challenge in fielding any autonomous systems is trust – can the system be trusted to perform as expected without horrific consequences? When and how to trust an autonomous learning machine is both a technical and non-technical challenge.
From a technical perspective, methods that can formally verify an autonomous learning system do not exist. Existing formal verification processes are regularly used to determine if a rule-based control system will perform within specified performance boundaries. For a learning system, however, it is difficult, if not impossible, to predict exactly which actions a learning system will take because it is designed to learn to do things it was not explicitly programmed to do. Bounded autonomy is one way to allow for existing methods to work; however, defining boundaries is also challenging and the limits it places on learning can prevent the machine from learning the best solutions.
As an alternative to formal verification, one could use exhaustive empirical testing to verify a learning system. This is the approach that Waymo and Uber are currently using in their development of autonomous vehicles. The most significant issues with this approach are the time and cost associated with doing the exhaustive testing. To conduct verification testing effectively, the system must be evaluated under all foreseeable conditions. Designing and running the tests are difficult and time-consuming. Additionally, if any major changes are made to the system during testing (due to failures or new technologies), then prior testing must be repeated to validate the new system. Finally, even if the system passes all tests there are still no guarantees as unforeseen conditions will more than likely occur.
On the non-technical side, people tend to be, understandably, skeptical of machines making decisions for them. Autonomous machines are a new thing and it is a bit unnerving to give up control, especially when mistakes in that control can lead to substantial monetary losses or even losses of life.
Given all these challenges, what is the answer? How do we gain trust? Should we even try?
While we certainly don’t have all the answers, we certainly need to try. Acceptance is often a slow process for major technical advances, but trust can be built. This trust must be earned, which will likely come down to taking measured risks over time. Learning machines are here to stay and, as time moves forward, we will become more accustomed to letting them perform increasingly complex functions. Technology will get better as will testing and verification processes, thus reducing risk and costs. The pioneering adopters will struggle and many will likely fail, but the potential benefits outweigh those risks. As scientists, developers, and users, we just need to be thoughtful and a little brave in how we research and employ autonomous learning machines.
Even more challenges
There are many more obstacles that must be overcome while developing an autonomous learning system based on reinforcement learning. Issues such as knowledge transfer, domain dynamics, catastrophic forgetting, and learning in the presence of multiple actors are all complicating factors that must be considered but are outside the scope of this article. The good news is that research and developments in reinforcement learning, and machine learning in general, are progressing very rapidly. Things that were once long-term, decades out, challenges, like mastering Go, are being overcome with increasing frequency. Challenges and issues described in this article will likely not remain for long. Subsequently, the most pressing challenge for many is staying at the forefront of research and cognizant of developments.
Near-term Applications: Picking the Low Hanging Fruit
Cyber security is a domain ripe for applications of autonomous learning systems. As discussed earlier, it shares many features with games that have made reinforcement learning solutions so successful. In this section we offer two such application areas: autonomous red teaming and dynamic maintenance scheduling. We discuss why autonomous learning solutions are needed and why these applications are excellent candidates for a reinforcement learning approach.
Autonomous Red Teaming and Penetration Testing
Red teaming and penetration testing, better known as “pen testing”, are security assessment processes used to determine the integrity, robustness, and resilience of a piece of software, computer system, or computer network. In each paradigm, the objective of the task is to cause the software system being assessed to do something it is not supposed to do through what are considered attacks. The induced effects include causing system crashes, unexpected errors, denial of services, and obtaining unauthorized access. It is an extremely useful service that many companies and organizations use to determine the strength of their security postures.
Presently, performing effective red team assessments requires professional hackers who have a great deal of experience and very specialized skills. Unfortunately, there is an increasingly disproportionate ratio of red team hackers to software systems that need assessments. This is great for those of us in the business of supplying computer security services, but the trend is bleak for everyone who relies on secure computing systems. Further, not all security assessments are equal. The skills and experience of each security analyst varies greatly between individuals as does the quality and comprehensiveness of their examinations. Autonomous red teaming and pen testing capabilities are required to provide consistent standards of service at scale. Reinforcement learning is an ideal technology for providing such capabilities.
Reinforcement learning for autonomous cyber security assessments is perfect for several reasons. First, cyber security assessments present an extremely low risk environment for a learning solution to try different things and gain experience. In fact, the objective of a red team assessment is to cause things to break, so a learning approach that systematically tries actions that are likely to cause faults is favorable. A learning system could try any number of actions to break a system in parallel gaining all the experience data it needs and using it to hone in on faults and vulnerabilities faster and more efficiently over time. Second, much of the techniques used in red teaming such as fuzzing, SQL injections, password cracking, etc. are episodic and repeated tasks. Each one of these tasks can be defined as individual reinforcement learning problem to be solved, generalized, and optimized. For example, in a fuzzing task different inputs are tried on a system to induce a fault. In general, there too many possible inputs to exhaustively test a system, so analysts instead use experience and intuition to devise a subset of possible inputs to fuzz with that are likely to cause a fault for a particular piece of software. Reinforcement learning, in theory, can learn such intuition from experiences to devise fuzzing policies from “similar” software platforms that are likely to cause faults more consistently and comprehensively. Finally, a reinforcement learning system that has been adequately trained to perform an assessment task with consistency can readily be copied and deployed at scale. Further, the experiences gathered from mass deployments can be shared and used by the learning algorithm to improve the policies over time and as software platforms and vulnerabilities evolve.
Autonomous red teams and pen testers are unlikely to replace human security analysts in the near or even distant future. Not only do such systems not exist yet, but many security vulnerabilities require considerable ingenuity to discover. Reinforcement learning approaches are getting better at devising novel solutions, but they still lag humans considerably when it comes to combining ideas across various tasks and domains. Instead, autonomous red teaming systems should be paired with humans and used in concert as another tool or partner for the analysts. This pairing will allow human analysts to focus on the more difficult to discover vulnerabilities so they can scale more effectively. And, perhaps the humans can teach the machines a few new tricks along the way.
Dynamic Maintenance Scheduling: Self Autonomic Optimization
Scheduling maintenance and other regular tasks that impact security posture, system availability, and performance are critical components of system administration. All businesses and organizations must provide reliable, effective, and secure computing platforms and networks to be successful. For any given organization, administrators must carefully design maintenance schedules for tasks, such as backups, patch deployments, system scans, service upgrades, and system replacements to minimize their impact on the mission of the organization and maximize security, resilience, and uptime. It is an exceptionally difficult task to manage and maintain as the composition of networks, numbers and types of services, threat-levels, and needs of an organization are in constant flux. As a result, maintenance schedules are frequently less than ideal, systems fail, services go down at inopportune times, employees are rarely satisfied with their IT departments, and system administrators lose a lot of hair and sleep. An autonomous learning system could reasonably remedy much of this situation by providing an autonomic scheduling capability that dynamically self-optimizes maintenance schedules as needs and contexts change.
Dynamic scheduling and optimization are a fantastic use of reinforcement learning technology because it is exactly the kind of thing it is designed to do. Reinforcement learning autonomously learns policies which is what schedules are. Not only can reinforcement learning automatically learn the schedules, but it can also learn how to optimize those schedules under very complex conditions. Reinforcement learning can continuously monitor thousands of different factors that impact when maintenance activities should be scheduled and dynamically respond to changes, threats, or failures as they happen at machine speeds. As reinforcement learning is a self-optimizing technology, it can learn policies that are customized specifically for the installations in which they are deployed. This allows them to function more effectively and efficiently than a one-size fits all automated solution that must have catchalls. Finally, system administration has very clear and measurable performance objectives (uptime, security incidents, etc.). These metrics make for easily defined reward functions that can be used by the learning system to derive schedules that optimize performance.
Autonomous scheduling of maintenance tasks using reinforcement learning is not without risks and challenges however. In this application there are real costs and consequences for deploying poor maintenance schedules. Applying patches, running virus scans, and rebooting all systems at 10 am would be a very bad decision. A learning system could conceivably do such a thing if it is inadequately trained and encounters an entirely unforeseen or experienced situation. Still, this problem could be mitigated if fail-safe policies are available that can be deployed if such a situation arises. The system could then use the experiences gathered during the deployment of the fail-safe policy to improve its policies and schedules. Also, if it is plausible to share experience data between various organizations it is possible to use those shared experiences to learn dramatically improved scheduling policies for all organizations involved.
Concluding Remarks
Machine learning may be the greatest technological achievement of our generation. It represents the future for many fields, but perhaps none more so than cyber operations. Reinforcement learning has moved the field forward by leaps and bounds by incorporating past experience into our models. In doing so, we can learn more complex problems and adapt to the near constant changes in the cyber landscape with a speed beyond what humans are capable of. The authors have begun such research and development, developing control problems for numerous cyber challenges, such as steganography, cyber hunt, and reverse engineering. At Assured Information Security, Inc. (AIS), we seek to research and develop novel applications of machine learning to various aspects of the cyber domain. The authors can be reached at wrightr [at] ainfosec [dot] com and dorar [at] ainfosec [dot] com, respectively, for questions or comments.
References
- M. Shirer and M. Daquila, “Worldwide Spending on Cognitive and Artificial Intelligence Systems Will Grow to $19.1 Billion in 2018,” International Data Corporation, 22 March 2018. [Online]. Available: https://www.idc.com/getdoc.jsp?containerId=prUS43662418. [Accessed 12 June 2018].
- J. Li, L. Sun, Q. Yan, Z. Li, W. Srisaan and H. Ye, “Significant Permission Identification for Machine Learning Based Android Malware Detection,” in IEEE Transactions on Industrial Informatics, 2018.
- N. Idika and A. Mathur, “A survey of malware detection techniques,” Purdue University, 2007.
- K. Bartos, M. Sofka and V. Franc, “Optimized Invariant Representation of Network Traffic for Detecting Unseen Malware Variants,” in USENIX Security Symposium, 2016.
- A. Tuor, S. Kaplan, B. Hutchinson, N. Nichols and S. Robinson, “Deep learning for unsupervised insider threat detection in structured cybersecurity data streams,” in arXiv, 2017.
- A. L. Buczak and E. Guven, “A survey of data mining and machine learning methods for cyber security intrusion detection,” IEEE Communications Surveys & Tutorials, vol. 18, no. 2, pp. 1153-1176, 2016.
- C. Livadas, R. Walsh, D. Lapsley and W. T. Strayer, “Using machine learning techniques to identify botnet traffic.,” in IEEE Conference on Local Computer Networks, 2006.
- A. Keromytis, “DARPA,” DARPA, 2017. [Online]. Available: https://www.darpa.mil/program/harnessing-autonomy-for-countering-cyberadversary-systems. [Accessed 12 June 2018].
- M. Staff and G. Flieshman, “Face ID on the iPhone X: Everything you need to know about Apple’s facial recognition,” Macworld, 25 December 2017. [Online]. Available: https://www.macworld.com/article/3225406/iphone-ipad/face-id-iphone-x-faq.html. [Accessed 12 June 2018].
- G. Tesauro, “Temporal difference learning and TD-Gammon,” Communications of the ACM, vol. 38, no. 3, pp. 58-68, 1995.
- V. Mnih, K. Kavukcuoglu, D. Silver, A. Rusu, J. Veness, M. Bellemare, A. Graves and e. al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, p. 529, 2015.
- Reuters, “Google to buy artificial intelligence company DeepMind,” Reuters, 26 January 2014. [Online]. Available: https://www.reuters.com/article/google-deepmind/google-to-buy-artificial-intelligence-company-deepmind-idUSL2N0L102A20140127. [Accessed 12 June 2018].
- Wikipedia, “Go (game),” wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Go_(game)#cite_note-144. [Accessed 12 June 2018].
- X. Xu, Y. Sun and Z. Huang, “Defending DDoS attacks using hidden Markov models and cooperative reinforcement learning,” in Pacific-Asia Workshop on Intelligence and Security Informatics, 2007.
- J. Cannady, “Next generation intrusion detection: Autonomous reinforcement learning of network attacks,” in 23rd national information systems security conference, 2000.
- R. Sutton and A. Barto, Reinforcement Learning: An Introduction, Cambridge: MIT press, 1998.