


Once upon a time, a brave knight was entrusted with the guarding of a valuable treasure. An evil wizard had designs on the treasure. It wasn’t known what mischief was planned or exactly what form the wizard might take. Would the villain try to seize and carry away the treasure? Or simply damage or destroy it? And how would the protector recognize the wizard or detect any evil-doings?
The knight considered many possible defenses: locking the treasure in a secure chamber, surrounding it with additional barriers and guardians, even casting a magic protective spell over it. As for anticipating the wizard’s attack, the knight realized that the best approach would be to try thinking like a villain — imagining how an evil-doer might behave.
Unfortunately, there is no “happily ever after” ending to this story, for as soon as the guardian thwarted one wizard’s advances another, more clever and subtle adversary arose … and the task was shown to be unending.
Is that your story, too? Securing systems from threats … threats from unknown and unseen adversaries … threats to confidentiality, integrity, or availability of systems and the information they contain. And are there tools to help you, the protector?
Software reliability engineering represents a well-established set of techniques supporting specification and assessment of dependability aspects of software-based systems. Application of these techniques to security concerns could provide helpful assistance for software assurance efforts.
Software reliability is defined as “the ability of a program to perform a required function under stated conditions for a stated period of time.” Quantitatively, this may be considered as “the probability that software will not cause the failure of a system for a specified time under specified conditions.” 1
Reliable software does what it is supposed to do. Unreliable software fails to meet expectations, but may do so in any of a number of ways. An unreliable software-based system may be unavailable, incorrect, vulnerable, or possibly even unsafe. This variety of inadequacies and failure modes includes both “sins of omission” (not behaving as intended) and also “sins of commission” (behaving in unintended ways).
A system in failure mode may be characterized by degraded performance, unexpected behavior, or complete loss of functionality. The severity with which the failure is regarded depends on the type of mission itself. What is the nature of our dependency on a given system? Failures of business-critical systems frustrate the accomplishment of their entrustedbusiness function. Systems handling sensitive personal or financial information can have security-breaching failure modes. Failures of safety-critical systems imperil safety.
Software unreliability may arise from errors such as specifying incomplete, ambiguous, or conflicting requirements; from inappropriate design choices; from incorrect implementation; or from any number of other opportunities for mistakes throughout the development process. These defects may often be subtle and very difficult to locate, given software’s complexity and immateriality.
John Musa 2 championed software reliability engineering (SRE) as a systematic and data-driven means for achieving desired levels of reliability. SRE represents “the application of statistical techniques to data collected during system development and operation to specify, predict, estimate, and assess the reliability of software-based systems.”
The classic Plan-Do-Check-Act cycle may be seen in the overarching approach of SRE:
Plan addresses setting reliability targets in measurable terms (“specify and predict”).
Do is the design and implementation of the system with those expectations.
Check represents all the appraisal activities up through system-level testing (“estimate and assess”).
Act then closes the loop and may lead to rework of the product or even retargeting of reliability goals.
At each stage of software development, available data are gathered and analyzed. The resulting reliability estimates then support data-based management decisions (See Figure 1).
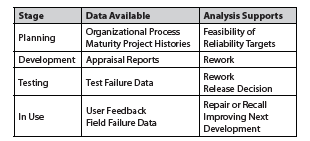
Figure 1. Lifecycle Software Reliability Measurements
At the planning stages of a project one may draw upon historical data from similar previously developed systems (including operational performance) as well as the organization’s assessed process maturity. Throughout development, defect detection provides opportunities for rework that can improve the final product. The timing of failures encountered in testing has been used to model projected operational reliability. Ideally SRE can support data-driven project decisions, most significantly the decision of when to release a product that is under development.
Consider that some of the most significant aspects of SRE include:
establishing quantitative reliability targets, constructing usage profiles of the operational system, and conducting statistically based testing to predict system reliability.
By analogy, security analysis could apply a similar approach with suitable modifications, such as:
establishing quantitative security targets including availability and loss function, using threat modeling to identify a variety of misuse/abuse cases, and rethinking reliability growth modeling in terms of security growth modeling.
Software security engineering would utilize activities across the development life cycle including:
- Initiation Phase of preliminary risk analysis, incorporating history of previous attacks on similar systems.
- Requirements Phase establishing appraisal management processes and conducting more detailed risk analysis.
- Design Phase focusing resources on specific modules, such as those designed to provide risk mitigation.
- Coding Phase with functional testing to begin at the unit level as individual modules are implemented.
- Testing Phase moving from unit testing through integration testing to complete system testing.
- Operational Phase requiring attention as deployment may involve configuration errors or encounters with unexpected aspects of the operational environment.
Reliability analysis has historically had to consider only failures due to accidental encounters with pre-existing software defects. However, security concerns arise from active attempts
to exploit system weaknesses – some of which may have been deliberately inserted by the same or other villains.
The subset of defects that might be exploited to breach security is typically referred to as vulnerabilities. Taking advantage of these weaknesses could adversely affect confidentiality, integrity, or accessibility of a system or its data.
The lower left quadrant in Figure 2 represents the realm that traditional reliability efforts have addressed: locating and removing defects inadvertently introduced into a system during
its development or maintenance. However, users are now encountering other situations, as represented in the upper left quadrant. Some issues result from design or implementation
tradeoffs in which potentially conflicting requirements (such as maximizing both efficiency and usability) have been satisfied through sub-optimizing one or both. More troublingly,
the topmost region of the upper left quadrant represents malicious acts such as the installation of back doors, trojans, or other deliberate weaknesses in the system. Someone with a knowledge of these weakness could then purposefully seek to exploit them, as shown in Figure 3.
Such malicious behavior also makes it more complicated to estimate the probability of system failure. A successful attack depends on a sequential set of factors in terms of knowledge,
skills, resources, and motivation:
What is the attacker’s knowledge about existing vulnerabilities?
How likely is an attacker to possess the skills required to exploit a known vulnerability?
How extensive are the resources (access, computing power, etc.) that the attacker might bring to bear?
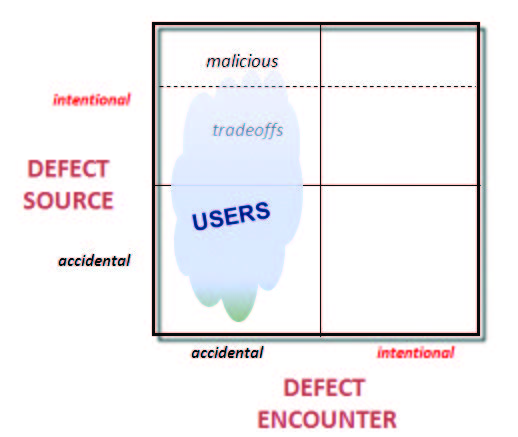
Figure 2. Distribution of Use
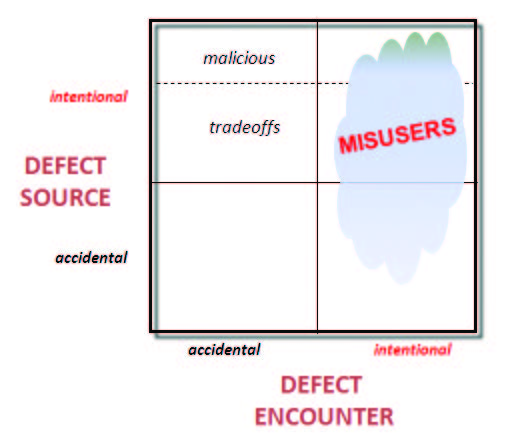
Figure 3. Distribution of Misuse
What motivations would keep a given attacker on task to successful completion of the attack?
Thus, a multiplicative series of probabilities must be considered. Threat modeling explores a range of possible attackers, all with different capabilities and incentives, and profiles these characteristics. Identifying potential threats to security is inherently more complex and uncertain than working within a well-defined community of stakeholders, all of whom wish the system to work successfully. First, the value of the system – its appeal to attackers – must be characterized across a range of potential misusers. Further, different attackers will themselves have different definitions of success, such as the extent to which they wish to remain undetected or anonymous.
Just as traditional usability and reliability assurance need a proper context for their design and interpretation, so too security assurance needs its own context if it is to provide useful insights. Threat modeling can be considered analogous to the development of operational profiles in reliability testing. Rather than being driven by customer- or user-supplied requirements, security assurance is typically mapped against anticipated attacks on the system. Hence the development of misuse (or abuse) cases to describe conditions under which attackers might threaten the system, in contrast to the traditional use cases, which describe “normal” interaction pattern.
Security assurance activities also require special attention. For instance, results of tests need to be considered with more nuance than simply noting whether or not security was compromised. They must be calibrated in terms of cumulative success factors:
- What knowledge about a given vulnerability was assumed in the test case?
- What specific skills and skill levels were employed within the test?
- How extensive were the resources that were required to execute the test?
- What motivations of an attacker would be sufficient to persist and produce a similar result?
Security growth modeling, analogous to reliability growth modeling, is an attempt to quantify how the projected security of a system increases with additional detection and removal of software vulnerabilities. Such insights would be crucial in allocating development and assurance resources, as well as making informed release or revision decisions. Security growth modeling relies on several analytical processes beyond those in traditional reliability growth modeling, including threat modeling.
The quantification of absolute security risk remains a long-range (if possibly unattainable) goal, but the approach described should allow for better understanding of relative risks and of the expected ROI from reduction of security risk exposure. The quest continues.
[Versions of this material were presented in a DACS webinar in August 2011 (http://www.thedacs.com/training/webinar/poll/index.php?pid=353) and at the Software Engineering Process Group – North America conference in March 2012. My thanks to the reviewers and facilitators at those events.]
End Notes
- Institute of Electrical and Electronics Engineers. 2008. IEEE Std 1633-2008, IEEE Recommended Practice on Software Reliability.
- Musa, John. 2005. “Software Reliability Engineering: Making Solid Progress.” SOFTWARE QUALITY PROFESSIONAL. Vol. 7, No. 4, pp 5-16.